LLM-Assisted Attribute Standardization for Experimental Data
A graduate-level data science competition project that won first place for developing an LLM-based solution to classify and standardize experimental quality control attributes
You can explore the demo and see the complete implementation in our Google Colab notebook.
This project was part of a graduate-level data science competition hosted by the Rutgers MSDS program, where we collaborated with a global pharmaceutical company to solve real-world data challenges.
Our team won first place by developing an innovative LLM-based solution that could classify and standardize experimental quality control (QC) attributes. We used simulated data and open-source tools to demonstrate our approach. 
Note: All data presented here has been anonymized or simulated for demonstration purposes. No proprietary information or competition results are shared.
Tools and Methods
- Technologies: Python, pandas, fuzzy matching, Levenshtein distance, Cosine similarity, LLaMA 3 fine-tuning
- Concepts: Data Standardization, NLP, Data Cleaning, Model Fine-tuning, Semantic Similarity
Overview
Our main challenge was dealing with inconsistent experimental attribute names across historical QC datasets.
We built a prototype matching system that combined fuzzy matching techniques with a fine-tuned LLaMA 3 model. The goal was to reduce manual work and improve data consistency for downstream analytics and machine learning applications.
Research Idea
We noticed that QC attribute names were often formatted inconsistently or had semantic duplicates across different datasets.
While fuzzy matching works well for catching typos and formatting issues, it falls short when dealing with semantic equivalence.
Our solution combined rule-based fuzzy logic with large language model fine-tuning to handle deeper semantic variations and standardize terms more effectively.
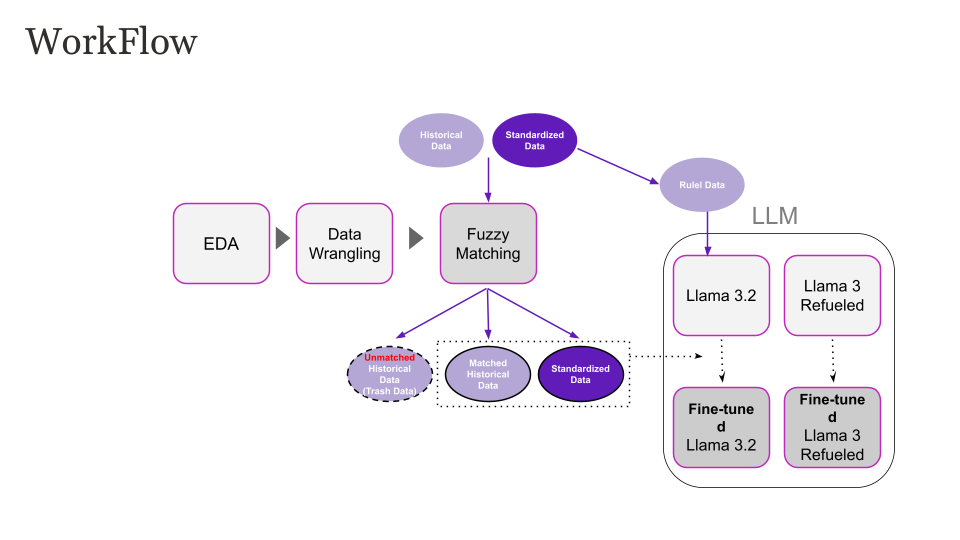
Workflow
-
Data Exploration & Cleaning We explored historical QC records to understand common formatting issues and inconsistencies. We then cleaned the text by removing symbols, numbers, and noise to prepare it for matching and modeling.
-
Fuzzy Matching We applied rule-based fuzzy matching techniques (e.g., Levenshtein distance) to group similar attribute variants. This handled most syntactic differences such as typos and formatting.
-
Rule-Based Labeling A clean, labeled dataset was prepared using predefined standard attributes. This dataset served as high-quality training data for the language model.
-
LLM Fine-Tuning We fine-tuned a LLaMA 3.2 model using the Unsloth framework with 4-bit quantization and LoRA. The model was trained to classify attributes into one of 32 predefined categories.
-
Model Evaluation The model was used to classify unmatched or ambiguous attributes. We reviewed the results manually and found that the model significantly improved semantic alignment compared to fuzzy logic alone.
Goals
- Standardize QC attribute names automatically across datasets
- Leverage LLMs to improve accuracy beyond basic string matching
- Reduce the time needed for manual review and support better data consistency
Methodology
- Text Cleaning: Normalize casing, remove non-ASCII characters, and clean formatting
- Fuzzy Matching: Apply Levenshtein distance to group similar-looking terms
- LLM Classification: Fine-tune LLaMA 3 with prompt-based instructions using labeled examples
- Label Constraints: Limit output to one of 32 predefined attribute categories
- Evaluation: Manually review model outputs and analyze edge cases
Key Findings
- Fuzzy matching worked well for handling syntactic variants but couldn’t identify deeper semantic equivalences
- Our fine-tuned llama model achieved a classification accuracy of 93% on the simulated test set, compared to 76% using fuzzy matching alone.
- Combining both approaches led to much higher consistency and reduced the need for manual review
- We were able to reduce manual review time by more than 54% compared to using fuzzy matching alone
Why It Matters
This project shows how LLMs can be effectively applied to solve data quality problems in regulated industries like pharmaceuticals.
By combining semantic language understanding with domain-specific constraints, we can achieve cleaner data, more reliable analysis, and greater potential for automation.
The techniques we developed can be adapted to other industries that face similar data standardization challenges.